Topic Model Evaluation
Topic models are widely used for analyzing unstructured text data, but they provide no guidance on the quality of topics produced. Evaluation is the key to understanding topic models. In this article, we’ll look at what topic model evaluation is, why it’s important, and how to do it.
Contents
- What is topic model evaluation?
- How to evaluate topic models
- Calculating coherence using Gensim in Python
- Limitations of coherence
- How to evaluate topic models – Recap
- Conclusion
- FAQs
Topic modeling is a branch of natural language processing that’s used for exploring text data.
It works by identifying key themes—or topics—based on the words or phrases in the data which have a similar meaning. Its versatility and ease of use have led to a variety of applications.
To learn more about topic modeling, how it works, and its applications here’s an easy-to-follow introductory article.
One of the shortcomings of topic modeling is that there’s no guidance on the quality of topics produced. If you want to know how meaningful the topics are, you’ll need to evaluate the topic model.
Evaluation is an important part of the topic modeling process that sometimes gets overlooked. For a topic model to be truly useful, some sort of evaluation is needed to understand how relevant the topics are for the purpose of the model.
In this article, we’ll look at topic model evaluation, what it is, and how to do it.
What is topic model evaluation?
Topic model evaluation is the process of assessing how well a topic model does what it is designed for.
When you run a topic model, you usually have a specific purpose in mind. It may be for document classification, to explore a set of unstructured texts, or some other analysis.
As with any model, if you wish to know how effective it is at doing what it’s designed for, you’ll need to evaluate it. This is why topic model evaluation matters.
How topic model evaluation helps
Evaluating a topic model can help you decide if the model has captured the internal structure of a corpus (a collection of text documents). This can be particularly useful in tasks like e-discovery, where the effectiveness of a topic model can have implications for legal proceedings or other important matters.
More generally, topic model evaluation can help you answer questions like:
- Are the identified topics understandable?
- Are the topics coherent?
- Does the topic model serve the purpose it is being used for?
Without some form of evaluation, you won’t know how well your topic model is performing or if it’s being used properly.
The challenges of topic model evaluation
Evaluating a topic model isn’t always easy, however.
If a topic model is used for a measurable task, such as classification, then its effectiveness is relatively straightforward to calculate (eg. measure the proportion of successful classifications).
But if the model is used for a more qualitative task, such as exploring the semantic themes in an unstructured corpus, then evaluation is more difficult.
In this article, we’ll focus on evaluating topic models that do not have clearly measurable outcomes. These include topic models used for document exploration, content recommendation, and e-discovery, amongst other use cases.
By evaluating these types of topic models, we seek to understand how easy it is for humans to interpret the topics produced by the model.
Put another way, topic model evaluation is about the ‘human interpretability’ or ‘semantic interpretability’ of topics.
How to evaluate topic models
There are a number of ways to evaluate topic models, including:
- Human judgment
- Observation-based, eg. observing the top ‘n‘ words in a topic
- Interpretation-based, eg. ‘word intrusion’ and ‘topic intrusion’ to identify the words or topics that “don’t belong” in a topic or document
- Quantitative metrics – Perplexity (held out likelihood) and coherence calculations
- Mixed approaches – Combinations of judgment-based and quantitative approaches
Let’s look at a few of these more closely.
Evaluating topic models – Human judgment
Observation-based approaches
The easiest way to evaluate a topic is to look at the most probable words in the topic.
This can be done in a tabular form, for instance by listing the top 10 words in each topic, or using other formats.
Word clouds
One visually appealing way to observe the probable words in a topic is through Word Clouds.
To illustrate, the following example is a Word Cloud based on topics modeled from the minutes of US Federal Open Market Committee (FOMC) meetings. The FOMC is an important part of the US financial system and meets 8 times per year.
The Word Cloud below is based on a topic that emerged from an analysis of topic trends in FOMC meetings from 2007 to 2020.
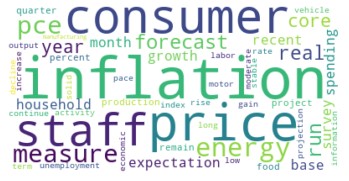
Topic modeling doesn’t provide guidance on the meaning of any topic, so labeling a topic requires human interpretation.
In the above Word Cloud, based on the most probable words displayed, the topic appears to be “inflation”.
You can see more Word Clouds from the FOMC topic modeling example here.
Termite
Beyond observing the most probable words in a topic, a more comprehensive observation-based approach called ‘Termite’ has been developed by Stanford University researchers.
Termite is described as a visualization of the term-topic distributions produced by topic models. In this description, ‘term’ refers to a ‘word’, so ‘term-topic distributions’ are ‘word-topic distributions’.
Termite produces meaningful visualizations by introducing two calculations:
- A ‘saliency’ measure, which identifies words that are more relevant for the topics in which they appear (beyond mere frequencies of their counts)
- A ‘seriation’ method, for sorting words into more coherent groupings based on the degree of semantic similarity between them
Termite produces graphs that summarize words and topics based on saliency and seriation. This helps to identify more interpretable topics and leads to better topic model evaluation.
You can see example Termite visualizations here.
Interpretation-based approaches
Interpretation-based approaches take more effort than observation-based approaches but produce better results. These approaches are considered a ‘gold standard’ for evaluating topic models since they use human judgment to maximum effect.
A good illustration of these is described in a research paper by Jonathan Chang and others (2009), that developed ‘word intrusion’ and ‘topic intrusion’ to help evaluate semantic coherence.
Word intrusion
In word intrusion, subjects are presented with groups of 6 words, 5 of which belong to a given topic and one which does not—the ‘intruder’ word. Subjects are asked to identify the intruder word.
To understand how this works, consider the following group of words:
[ dog, cat, horse, apple, pig, cow ]
Can you spot the intruder?
Most subjects pick ‘apple’ because it looks different from the others (all of which are animals, suggesting an animal-related topic for the others).
Now, consider:
[ car, teacher, platypus, agile, blue, Zaire ]
Which is the intruder in this group of words?
It’s much harder to identify, so most subjects choose the intruder at random. This implies poor topic coherence.
Topic intrusion
Similar to word intrusion, in topic intrusion subjects are asked to identify the ‘intruder’ topic from groups of topics that make up documents.
In this task, subjects are shown a title and a snippet from a document along with 4 topics. Three of the topics have a high probability of belonging to the document while the remaining topic has a low probability—the ‘intruder’ topic.
As for word intrusion, the intruder topic is sometimes easy to identify, and at other times it’s not.
The success with which subjects can correctly choose the intruder topic helps to determine the level of coherence.
Evaluating topic models – Quantitative metrics
While evaluation methods based on human judgment can produce good results, they are costly and time-consuming to do.
Moreover, human judgment isn’t clearly defined and humans don’t always agree on what makes a good topic.
In contrast, the appeal of quantitative metrics is the ability to standardize, automate and scale the evaluation of topic models.
Held out likelihood or perplexity
A traditional metric for evaluating topic models is the ‘held out likelihood’. This is also referred to as ‘perplexity’.
Perplexity is calculated by splitting a dataset into two parts—a training set and a test set.
The idea is to train a topic model using the training set and then test the model on a test set that contains previously unseen documents (ie. held-out documents).
Likelihood is usually calculated as a logarithm, so this metric is sometimes referred to as the ‘held out log-likelihood’.
The perplexity metric is a predictive one. It assesses a topic model’s ability to predict a test set after having been trained on a training set.
In practice, around 80% of a corpus may be set aside as a training set with the remaining 20% being a test set.
Although the perplexity metric is a natural choice for topic models from a technical standpoint, it does not provide good results for human interpretation.
This was demonstrated by research, again by Jonathan Chang and others (2009), which found that perplexity did not do a good job of conveying whether topics are coherent or not.
When comparing perplexity against human judgment approaches like word intrusion and topic intrusion, the research showed a negative correlation. This means that as the perplexity score improves (i.e., the held out log-likelihood is higher), the human interpretability of topics gets worse (rather than better).
The perplexity metric, therefore, appears to be misleading when it comes to the human understanding of topics.
Are there better quantitative metrics available than perplexity for evaluating topic models?
Coherence
One of the shortcomings of perplexity is that it does not capture context, i.e., perplexity does not capture the relationship between words in a topic or topics in a document.
The idea of semantic context is important for human understanding.
To overcome this, approaches have been developed that attempt to capture context between words in a topic.
They use measures such as the conditional likelihood (rather than the log-likelihood) of the co-occurrence of words in a topic. These approaches are collectively referred to as ‘coherence’.
There’s been a lot of research on coherence over recent years and as a result, there are a variety of methods available. A useful way to deal with this is to set up a framework that allows you to choose the methods that you prefer.
Such a framework has been proposed by researchers at AKSW.
Using this framework, which we’ll call the ‘coherence pipeline’, you can calculate coherence in a way that works best for your circumstances (e.g., based on the availability of a corpus, speed of computation, etc.).
The coherence pipeline offers a versatile way to calculate coherence.
It is also what Gensim, a popular package for topic modeling in Python, uses for implementing coherence (more on this later).
The coherence pipeline is made up of four stages:
- Segmentation
- Probability estimation
- Confirmation
- Aggregation
These four stages form the basis of coherence calculations and work as follows:
Segmentation sets up word groupings that are used for pair-wise comparisons.
Let’s say that we wish to calculate the coherence of a set of topics.
Coherence calculations start by choosing words within each topic (usually the most frequently occurring words) and comparing them with each other, one pair at a time.
Segmentation is the process of choosing how words are grouped together for these pair-wise comparisons.
Word groupings can be made up of single words or larger groupings.
For single words, each word in a topic is compared with each other word in the topic.
For 2- or 3-word groupings, each 2-word group is compared with each other 2-word group, and each 3-word group is compared with each other 3-word group, and so on.
Comparisons can also be made between groupings of different sizes, for instance, single words can be compared with 2- or 3-word groups.
Probability estimation refers to the type of probability measure that underpins the calculation of coherence.
To illustrate, consider the two widely used coherence approaches of UCI and UMass:
- UCI is based on point-wise mutual information (PMI) calculations. This is given by:
PMI(wi,wj) = log[(P(wi,wj) + e) / P(wi).P(wj)], for wordswiandwjand some small numbere, and whereP(wi)is the probability of wordioccurring in a topic andP(wi,wj)is the probability of both wordsiandjappearing in a topic. Here, the probabilities are based on word co-occurrence counts. - UMass caters to the order in which words appear and is based on the calculation of:
log[(P(wi,wj) + e) / P(wj)], withwi,wj,P(wi)andP(wi,wj)as for UCI. Here, the probabilities are conditional, sinceP(wi|wj) = [(P(wi,wj) / P(wj)], which we know from Bayes’ theorem. So, this approach measures how much a common word appearing within a topic is a good predictor for a less common word in the topic.
Confirmation measures how strongly each word grouping in a topic relates to other word groupings (i.e., how similar they are).
There are direct and indirect ways of doing this, depending on the frequency and distribution of words in a topic.
Aggregation is the final step of the coherence pipeline.
It’s a summary calculation of the confirmation measures of all word groupings, resulting in a single coherence score.
This is usually done by averaging the confirmation measures using the mean or median. Other calculations may also be used, such as the harmonic mean, quadratic mean, minimum or maximum.
Coherence is a popular way to quantitatively evaluate topic models and has good coding implementations in languages such as Python (e.g., Gensim).
| Method | Description |
| Human judgment approaches | |
| Observation-based | Observe the most probable words in the topic |
| Interpretation-based | Word intrusion and topic intrusion |
| Quantitative approaches | |
| Perplexity | Calculate the held out log-likelihood |
| Coherence | Calculate the conditional likelihood of co-occurrence |
To see how coherence works in practice, let’s look at an example.
Calculating coherence using Gensim in Python
Gensim is a widely used package for topic modeling in Python.
It uses Latent Dirichlet Allocation (LDA) for topic modeling and includes functionality for calculating the coherence of topic models.
As mentioned, Gensim calculates coherence using the coherence pipeline, offering a range of options for users.
The following example uses Gensim to model topics for US company earnings calls.
These are quarterly conference calls in which company management discusses financial performance and other updates with analysts, investors, and the media. They are an important fixture in the US financial calendar.
The following code calculates coherence for a trained topic model in the example:
# Set up coherence model
coherence_model_lda = gensim.models.CoherenceModel(model=lda_model, texts=ECallDocuments, dictionary=ID2word, coherence='c_v')
# Calculate and print coherence
coherence_lda = coherence_model_lda.get_coherence()
print('\nCoherence Score:', coherence_lda)
The coherence method that was chosen is “c_v”. This is one of several choices offered by Gensim.
Other choices include UCI (“c_uci”) and UMass (“u_mass”).
For more information about the Gensim package and the various choices that go with it, please refer to the Gensim documentation.
Gensim can also be used to explore the effect of varying LDA parameters on a topic model’s coherence score. This helps to select the best choice of parameters for a model.
The following code shows how to calculate coherence for varying values of the alpha parameter in the LDA model:
# Coherence values for varying alpha
def compute_coherence_values_ALPHA(corpus, dictionary, num_topics, seed, texts, start, limit, step):
coherence_values = []
model_list = []
for alpha in range(start, limit, step):
model = gensim.models.LdaMulticore(corpus=corpus, id2word=dictionary, num_topics=num_topics, random_state=seed, alpha=alpha/10, passes=100)
model_list.append(model)
coherencemodel = gensim.models.CoherenceModel(model=model, texts=texts, dictionary=dictionary, coherence='c_v')
coherence_values.append(coherencemodel.get_coherence())
return model_list, coherence_values
model_list, coherence_values = compute_coherence_values_ALPHA(dictionary=ID2word, corpus=trans_TFIDF, num_topics=NUM_topics, seed=SEED, texts=ECallDocuments, start=1, limit=10, step=1)
# Plot graph of coherence values by varying alpha
limit=10; start=1; step=1;
x_axis = []
for x in range(start, limit, step):
x_axis.append(x/10)
plt.plot(x_axis, coherence_values)
plt.xlabel("Alpha")
plt.ylabel("Coherence score")
plt.legend(("coherence"), loc='best')
plt.show()The above code also produces a chart of the model’s coherence score for different values of the alpha parameter:
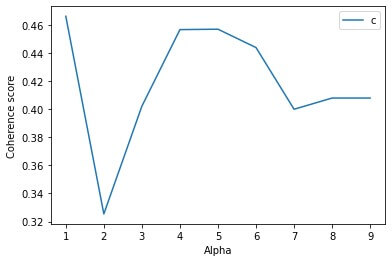
This helps in choosing the best value of alpha based on coherence scores.
In practice, you should check the effect of varying other model parameters on the coherence score. You can see how this is done in the US company earning call example here.
The overall choice of model parameters depends on balancing the varying effects on coherence, and also on judgments about the nature of the topics and the purpose of the model.
Limitations of coherence
Despite its usefulness, coherence has some important limitations.
According to Matti Lyra, a leading data scientist and researcher, the key limitations are:
- Variability—The aggregation step of the coherence pipeline is typically calculated over a large number of word-group pairs. While this produces a metric (e.g., mean of the coherence scores), there’s no way of estimating the variability of the metric. This means that there’s no way of knowing the degree of confidence in the metric. Hence, although we can calculate aggregate coherence scores for a topic model, we don’t really know how well that score reflects the actual coherence of the model (relative to statistical noise).
- Comparability—The coherence pipeline allows the user to select different methods for each part of the pipeline. This, combined with the unknown variability of coherence scores, makes it difficult to meaningfully compare different coherence scores or coherence scores between different models.
- Reference corpus—The choice of reference corpus is important. In cases where the probability estimates are based on the reference corpus, then a smaller or domain-specific corpus can produce misleading results when applied to a set of documents that are quite different from the reference corpus.
- “Junk” topic—Topic modeling provides no guarantees about the topics that are identified (hence the need for evaluation) and sometimes produces meaningless, or “junk”, topics. These can distort the results of coherence calculations. The difficulty lies in identifying these junk topics for removal—it usually requires human inspection to do so. But, involving humans in the process defeats the very purpose of using coherence, ie. to automate and scale topic model evaluation.
With these limitations in mind, what’s the best approach for evaluating topic models?
How to evaluate topic models—Recap
This article has hopefully made one thing clear—topic model evaluation isn’t easy!
Unfortunately, there’s no straightforward or reliable way to evaluate topic models to a high standard of human interpretability.
Also, the very idea of human interpretability differs between people, domains, and use cases.
Nevertheless, the most reliable way to evaluate topic models is by using human judgment. But this takes time and is expensive.
In terms of quantitative approaches, coherence is a versatile and scalable way to evaluate topic models. But it has limitations.
In practice, you’ll need to decide how to evaluate a topic model on a case-by-case basis, including which methods and processes to use.
A degree of domain knowledge and a clear understanding of the purpose of the model helps.
The thing to remember is that some sort of evaluation will be important in helping you assess the merits of your topic model and how to apply it.
Conclusion
Topic model evaluation is an important part of the topic modeling process. This is because topic modeling offers no guidance on the quality of topics produced.
Evaluation helps you assess how relevant the produced topics are, and how effective the topic model is.
But evaluating topic models is difficult to do.
There are various approaches available, but the best results come from human interpretation. But this is a time-consuming and costly exercise.
Quantitative evaluation methods offer the benefits of automation and scaling.
Coherence is the most popular of these and is easy to implement in widely used coding languages, such as Gensim in Python.
In practice, the best approach for evaluating topic models will depend on the circumstances.
Domain knowledge, an understanding of the model’s purpose, and judgment will help in deciding the best evaluation approach.
Keep in mind that topic modeling is an area of ongoing research—newer, better ways of evaluating topic models are likely to emerge.
In the meantime, topic modeling continues to be a versatile and effective way to analyze and make sense of unstructured text data.
And with the continued use of topic models, their evaluation will remain an important part of the process.
FAQs
Perplexity is a measure of how successfully a trained topic model predicts new data. In LDA topic modeling of text documents, perplexity is a decreasing function of the likelihood of new documents. In other words, as the likelihood of the words appearing in new documents increases, as assessed by the trained LDA model, the perplexity decreases. And vice-versa. The idea is that a low perplexity score implies a good topic model, ie. one that is good at predicting the words that appear in new documents. Although this makes intuitive sense, studies have shown that perplexity does not correlate with the human understanding of topics generated by topic models. Hence, while perplexity is a mathematically sound approach for evaluating topic models, it is not a good indicator of human-interpretable topics.
Coherence measures the degree of semantic similarity between the words in topics generated by a topic model. The more similar the words within a topic are, the higher the coherence score, and hence the better the topic model. There are a number of ways to calculate coherence based on different methods for grouping words for comparison, calculating probabilities of word co-occurrences, and aggregating them into a final coherence measure. Coherence is a popular approach for quantitatively evaluating topic models and has good implementations in coding languages such as Python and Java.
In LDA topic modeling, the number of topics is chosen by the user in advance. This is sometimes cited as a shortcoming of LDA topic modeling since it’s not always clear how many topics make sense for the data being analyzed. In practice, judgment and trial-and-error are required for choosing the number of topics that lead to good results.
There are various measures for analyzing—or assessing—the topics produced by topic models. These include quantitative measures, such as perplexity and coherence, and qualitative measures based on human interpretation. There is no clear answer, however, as to what is the best approach for analyzing a topic. Ultimately, the parameters and approach used for topic analysis will depend on the context of the analysis and the degree to which the results are human-interpretable.